

人や動物の行動を学習して、達人技の模倣までをも可能とする「逆強化学習」。
「エージェント・行動・方策・環境」のパラメーターをAI自身が試行錯誤して、よりよい報酬を導き出していく強化学習の「逆」を意味する学習方法とは想像ができても、実際の定義や実例を知っている方は少ないかもしれません。
今回は、逆強化学習の事例を紹介します。また、学習方法も解説していきますので、ぜひ参考にしてください。
AI導入のノウハウ・活用方法をチェック

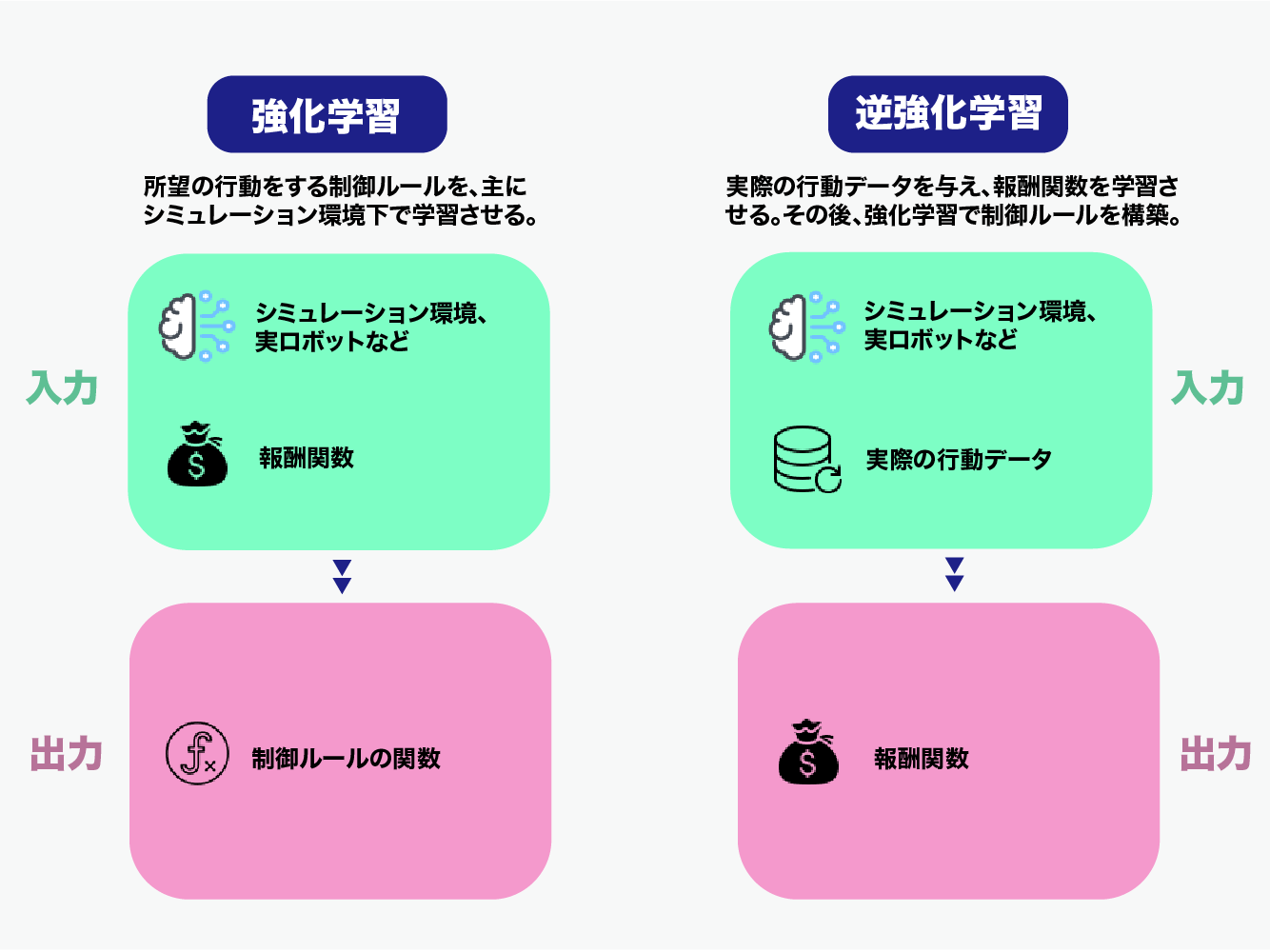
逆強化学習とは
参考サイト:https://www.slideshare.net/yutaroogawa1116/20200925-238655136
逆強化学習(Inverse Reinforcement Learning, IRL)とは、強化学習の一種であり、人間がどのように報酬を設計しているのかを推定することで、エージェントが意図する動作を理解することを目的としています。
一般的な強化学習では、報酬関数が与えられ、エージェントは報酬を最大化するように行動します。しかし、実際の問題では、報酬関数が事前に与えられているわけではありません。例えば、ロボットが道を歩く場合、報酬は「目的地に到達すること」だけではありません。それに加え、歩く際に避けなければならない障害物や、歩道を歩くべきであるなど、多数の制約条件があります。
逆強化学習では、エージェントがどのような報酬関数に従って行動するかを推定することで、報酬関数自体を特定します。この手法によって、人間の専門家が実際に使用するような、より複雑な報酬関数を理解することができ、より高度な問題に対処できるようになります。
以下では、逆強化学習が誕生した背景と、その学習方法について詳しくみていきましょう。
逆強化学習の誕生背景
逆強化学習の誕生背景には、人間の専門家が開発した高度な制御システムを、人工知能が自律的に理解する必要性があります。
従来の強化学習では、人工知能エージェントが最適な行動を学習するために、報酬関数が与えられています。しかし、報酬関数を設計すること自体が困難であり、経験や専門知識が必要です。また、現実の問題では、報酬関数が既知であることは珍しく、報酬関数を理解することが重要です。
逆強化学習は、人間の専門家が実際に使用する報酬関数を学習するための手法として開発されました。この手法を使用することで、人工知能エージェントが自律的に問題を解決するために、人間の専門知識や経験を活用することができます。逆強化学習は、現在では自動運転やロボット制御などの分野で活用されています。
逆強化学習の原理
ここでは「逆強化学習」の原理を解説した後、「強化学習」との違いも紹介していきます。
具体的には、逆強化学習では、人間の専門家が「望ましい」と判断する行動を取るようにエージェントを学習させます。その結果、エージェントが取った行動によって得られた報酬信号を解析し、その背後にある報酬関数を推定します。
逆強化学習では、報酬関数を推定するために、最尤推定法や貝殻法などの統計的手法が使用されます。これらの手法を用いることで、報酬関数を正確に推定することが可能となります。
推定された報酬関数を使用することで、エージェントは人間の専門家が意図する動作を理解し、複雑な問題に対処することができます。逆強化学習は、自動運転やロボット制御などの分野で活用されており、より高度な自律制御システムの開発に貢献しています。
逆強化学習の2つの学習方法
ここでは逆強化学習の2つの学習方法「模倣学習」「行動解析」について解説します。
1.模倣学習
模倣学習は、人間の専門家の行動を真似ることによって報酬関数を学習する方法です。つまり、人間の専門家が望ましいと判断する行動をエージェントが真似ることで、報酬関数を推定します。具体的には、人間の専門家が取った行動とその結果を記録し、それらをエージェントが再現することで報酬関数を学習します。模倣学習は、高度なタスクを実行するために必要な専門知識や技術を自動的に取り込むことができるため、自動運転やロボット制御などの分野で広く活用されています。
2.行動解析
行動解析は、エージェントの行動を解析して報酬関数を学習する方法です。つまり、エージェントが実際に取った行動とその結果から、報酬関数を推定します。行動解析では、エージェントの行動を記録することで、その行動がどのような報酬をもたらしたのかを分析し、報酬関数を推定します。行動解析は、模倣学習と異なり、人間の専門家が介入せずにエージェントが自律的に行動を学習することができるため、より一般的な状況においても応用が可能です。また、エージェントが学習する過程で、未知の報酬関数を発見することができるという特徴があります。行動解析は、自律的なエージェントの開発において非常に有用な手法の1つです。
逆強化学習の主な手法
続いて、逆強化学習の主な手法について紹介します。
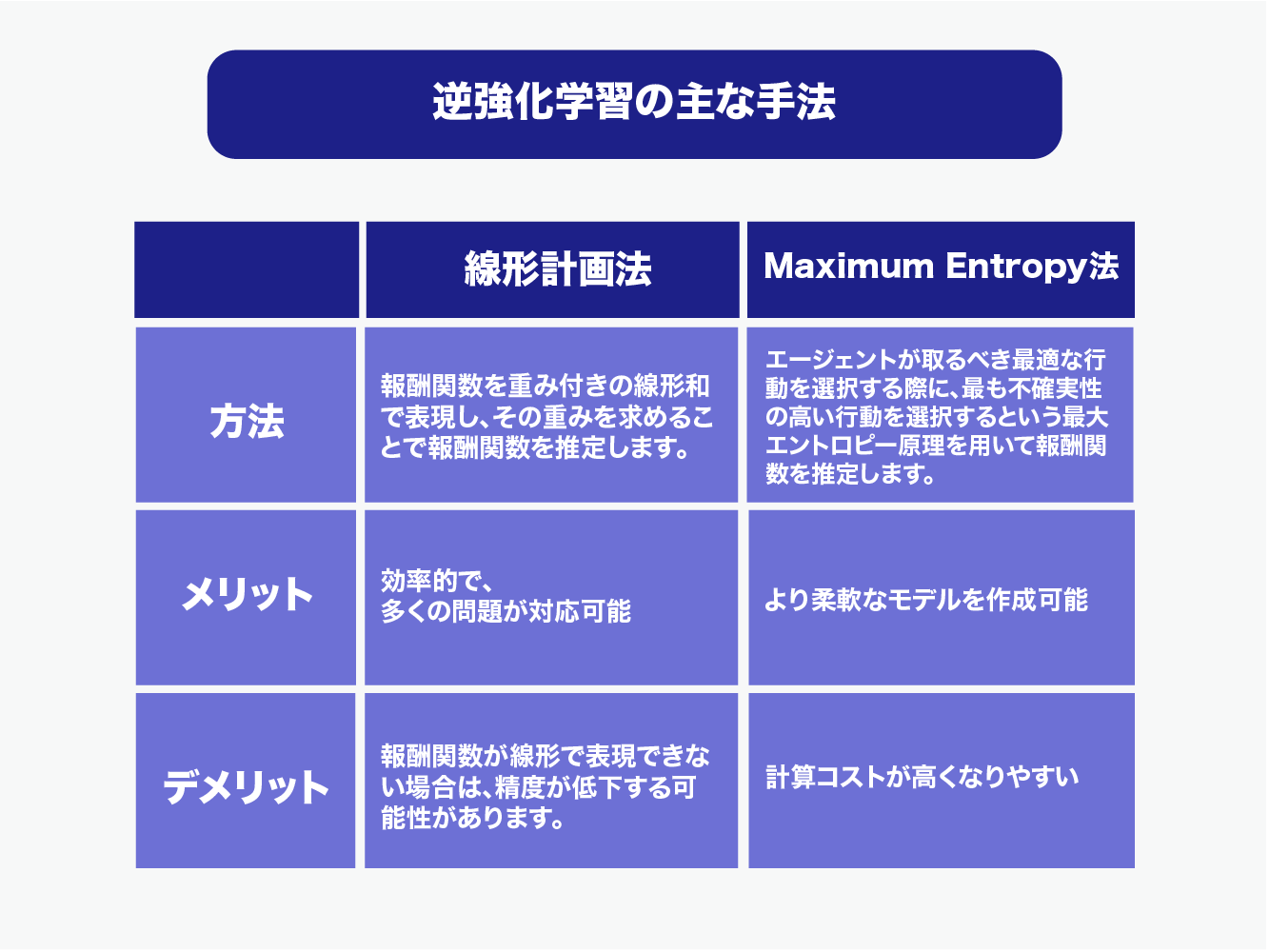
線形計画法
線形計画法は、逆強化学習において報酬関数を推定するための手法の1つで、報酬関数を線形の制約条件で表現する方法です。具体的には、報酬関数を重み付きの線形和で表現し、その重みを求めることで報酬関数を推定します。線形計画法は、制約条件が線形であるため、効率的な最適化手法が存在し、多くの問題に対応できる汎用的な手法です。しかし、報酬関数が線形で表現できない場合は、精度が低下する可能性があります。
Maximum Entropy法(最大エントロピー法)
Maximum Entropy法は、逆強化学習において報酬関数を推定するための手法の1つで、エージェントの行動から推定される報酬分布のエントロピーを最大化することで報酬関数を推定する方法です。具体的には、エージェントが取るべき最適な行動を選択する際に、最も不確実性の高い行動を選択するという最大エントロピー原理を用いて報酬関数を推定します。Maximum Entropy法は、報酬関数が線形で表現できない場合にも対応でき、より柔軟なモデルを作成することができます。しかし、計算コストが高くなりやすいというデメリットがあります。
※「エントロピー」とは、不確実性・不規則性を表す言葉です。
逆強化学習の事例を紹介
ここでは、逆強化学習を活用した事例を紹介します。逆強化学習を活用したAIが、いかに社会生活に必要なのかを分かっていただけるでしょう。
生活道路における危険予知運転
逆強化学習を用いて、交通事故を回避するための運転戦略を学習する研究があります。カメラやレーダーなどのセンサーで取得したデータを基に、運転手がどのような判断を行っているかを逆推定し、その判断に基づいて運転するように学習します。
参照:逆強化学習を用いた生活道路における危険予知運転モデリング
ウェブサイトのアクセス解析
ウェブサイトのアクセスログを用いて、ユーザーが何を求めているのかを逆推定し、ウェブサイトの改善に役立てる研究があります。逆強化学習を用いることで、ユーザーが何を求めているのかを正確に理解し、それに合わせたコンテンツや機能を提供することができます。
ロボットの動作制御
ロボットの動作制御に逆強化学習を適用することで、ロボットが自己学習によって、人間が望む動作を実現することができます。例えば、ロボットが複雑な環境下での物体の掴み方や、移動時の軌道設計を学習することができます。
参照:三菱電機、逆強化学習を活用して人と機械が混在する生産・物流現場での作業効率化を支援する「人と協調するAI」を開発 | IoT NEWS
医療分野での治療過程の質の向上
逆強化学習を用いて、医療分野での治療過程の最適化に取り組む研究があります。医療現場での医師の判断や、治療方針などを逆推定し、最適な治療プランを作成することができます。また、治療過程の透明性を高め、患者さんへの説明や、病気の理解にも役立てることができます。

逆強化学習の課題とは
ここでは、逆強化学習の解決すべき課題と、その解決法を見ていきます。逆強化学習は、課題の解決により、さらに幅広い活用を可能にしていくと予想されています。
模倣困難な事象の存在
逆強化学習では、報酬関数を推定するために、人間の行動を観察する必要があります。しかし、人間の行動が不可解であったり、あるいは行動が矛盾している場合、報酬関数の推定が困難になります。このような場合、正しい報酬関数を推定することができず、学習したエージェントの行動が人間の行動と異なってしまう可能性があります。
課題の解決手段
逆強化学習は、環境が非常に複雑な場合には、適切に報酬関数を推定することが難しくなります。これは、報酬関数を推定するために必要な計算量が膨大になるためです。また、環境内に存在する多数の変数や要素が互いに相互作用している場合、報酬関数を推定することが複雑になります。
課題解決の方法

これらの課題を解決するために、以下のような手段が取られています。
複数の逆強化学習アルゴリズムの開発
現在、様々な逆強化学習のアルゴリズムが開発されており、特定の問題に適したアルゴリズムを選択することで、課題を克服することができます。
報酬関数のデザインの工夫
報酬関数を適切に設計することで、逆強化学習の性能を向上させることができます。報酬関数の設計には、ドメイン知識や、人間の行動の特性に関する知識を用いることが有効です。
深層学習の応用
深層学習によるモデルの学習によって、非常に複雑な問題にも対応できるようになってきています。また、深層学習を逆強化学習に応用することで、より高い性能を実現することができます。
AidiotならAIを活用したビジネスサポートを実現!
Aidiotは多くの実績と高い信頼をもち、AI(人工知能)を駆使した業務の効率化、デジタルプラットフォームの開発・運用をサポートしています。
また、「データで社会課題を解決する」をスローガンに公共事業にも積極的に取り組み、内閣府が推進する国家重点プロジェクトSIPでの実証実験や、東京データプラットフォーム協議会への参画などを実現しています。
興味のある方は、ぜひアイディオットの活用をご検討ください。
お問い合わせはこちらから
まとめ
今回は、達人技を模倣する学習法など、逆強化学習の事例を紹介しました。逆強化学習は、強化学習では対応できない問題を解決する手段として登場しました。今後も多くの分野での活用が予想されます。
しかし、実際の活用には専門のエンジニアの存在は必須です。事業でのAI活用において、信頼のおけるサポート会社は心強い味方となるでしょう。弊社では、DXに精通したメンバーが揃っており、サプライチェーン全体最適化、データ基盤の構築、DX支援、ソフトウェアの開発などを行っております。気になることがございましたらお気軽にご相談ください。
この記事の執筆・監修者
 Aidiot編集部
Aidiot編集部「BtoB領域の脳と心臓になる」をビジョンに、データを活用したアルゴリズムやソフトウェアの提供を行う株式会社アイディオットの編集部。AI・データを扱うエンジニアや日本を代表する大手企業担当者をカウンターパートにするビジネスサイドのスタッフが記事を執筆・監修。近年、活用が進んでいるAIやDX、カーボンニュートラルなどのトピックを分かりやすく解説します。






